W tym artykule przedstawiam technologie i narzędzia, które należy moim zdaniem znać, aby ubiegać się o pracę jako Młodszy Programista Java. Wspomnę także o kilku przydatnych umiejętnościach. Nie stanowią one kompletnej listy – wybrałem te z nich, które są moim zdaniem najistotniejsze, aby osoba przychodząca do pracy mogła czuć się w niej pewnie. Przy każdym z zagadnień znajdziesz:
- krótki opis czym jest dana technologia/narzędzie i do czego służy,
- wymagany poziom znajomości.
Ciężko w prosty sposób określić wymagany poziom wiedzy, dlatego będą pokrótce opisywał, co powinniśmy na dany temat wiedzieć lub co powinieneś być w stanie zrobić.
Gdybyśmy wybrali inny język programowania jako nasz cel, to większość z opisanych tu narzędzi i technologii by się nie zmieniła. Wiele z nich jest niezależnych od języka programowania, z którego korzystamy. Przy omawianych zagadnieniach umieszczę informację, czy są one raczej związane z pracą jako programista Java, czy też daną technologię/narzędzie znajdziemy też na innych projektach.
Zwrócę jeszcze uwagę na jeden fakt: każdy projekt jest inny. Na projektach stosowane są różne narzędzia, biblioteki i technologie. W związku z tym, przy omawianiu niektórych z nich umieściłem alternatywy, z którymi można się spotkać pracując jako programista.
Artykuł podzielony jest na trzy części:
- Część 1 – Najistotniejsze technologie, narzędzia, umiejętności.
- Część 2 – Istotne zagadnienia z wymaganą podstawową znajomością.
- Część 3 – Dodatkowe technologie i narzędzia, które warto znać.
Część 2 – Istotne zagadnienia z wymaganą podstawową znajomością¶
Spis treści
Hibernate¶
Hibernate to biblioteka służąca do mapowania obiektów klas Java na tabele w relacyjnej bazie danych. Jest to tzw. mapowanie relacyjno-obiektowe. Dzięki użyciu adnotacji, możemy w prosty sposób zmapować klasę na odpowiadającą jej tabelę w bazie danych.
Hibernate ułatwia zapis obiektów do bazy danych, a także ich odczyt, dzięki czemu nie musimy sami pisać zapytań SQL. Hibernate obsługuje także powiązania pomiędzy tabelami i potrafi pobrać zależne rekordy do odpowiednich list obiektów. Dla przykładu, pobierając z bazy danych obiekt klasy Zamowienie, pobrane też mogą zostać produkty zakupione przez klienta w ramach zamówienia.
Hibernate to popularne rozwiązanie i jest często spotykane na projektach, które korzystają z języka Java. Dobrze byłoby znać podstawy mapowania klas na tabele i rozumieć, jak i kiedy Hibernate pobiera i zapisuje dane naszych obiektów.
Dobrym miejscem, aby rozpocząć naukę Hibernate, jest oficjalna strona, na której znajdziesz krótki artykuł dla nowych użytkowników, a także dłuższy, bardziej szczegółowy dokument o korzystaniu z Hibernate:
https://docs.jboss.org/hibernate/orm/5.4/quickstart/html_single/ https://docs.jboss.org/hibernate/orm/5.4/userguide/html_single/Hibernate_User_Guide.html
Alternatywa: na niektórych projektach wykorzystywany jest moduł Spring o nazwie Spring Data. Ułatwia on działanie z różnego rodzaju bazami danych, nie tylko relacyjnymi.
Czy występuje tylko na projektach Java: tak, ale pojęcie mapowania obiektowo-relacyjnego jest ogólnym zagadnieniem związanym z programowaniem, więc można się z nim spotkać także na projektach korzystających z innych języków programowania.
XML¶
XML to język znaczników (markup language). Pozwala on na opisywanie dowolnego rodzaju danych.
Dane opisane w plikach XML są zrozumiałe przez człowieka, a także można je odczytywać w programach komputerowych.
XML jest tak powszechny, że jego znajomość na poziomie podstawowym jest wymagana, aby pracować jako programista. To w XMLu konfigurujemy nasze projekty korzystające z Mavena. XML był także kiedyś jedynym sposobem na skonfigurowanie programów napisanych w języku Java, które korzystały z frameworku Spring. Od kilku lat Springa możemy konfigurować w klasach Java, ale starsze projekty cały czas korzystają z konfiguracji XMLowej.
Pliki XML to pliki tekstowe o rozszerzeniu .xml – możesz edytować je w dowolnym edytorze, np. w Notepad++.
Podstawy XML są łatwe do nauczenia – dane opakowujemy w tzw. tagi. Tag otwierający ma postać <pewien_tag>, a zamykający </pewien_tag>. Nazwa tagu jest dowolna. Tagi mogą być zagnieżdżone oraz mogą mieć atrybuty. Spójrzmy na prosty przykład dokumentu XML. Ten konkretny przykład to plik konfiguracyjny pom.xml prostego projektu Mavenowego z mojego kursu Podstawy Maven:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.kursjava.maven</groupId>
<artifactId>hello-maven</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
</project>
W powyższym listingu tagi to np. <modelVersion> i <groupId>, a opisują one wartości 4.0.0 i com.kursjava.maven. Atrybuty to np. xmlns i encoding, a wartości tych atrybutów to http://maven.apache.org/POM/4.0.0 i UTF-8. Te podstawowe informacje w zasadzie wystarczą Ci na początek pracy z dokumentami XML.
Kluczową informacją tutaj jest to, że w dokumentach XML możesz przechowywać dowolne dane, które będą zawarte w tagach, które będą miały dla Ciebie znaczenie. Dla przykładu, poniższy listing to prawidłowy dokument XML:
<listaZakupow> <produkt rodzaj="rozpuszczalna">Kawa</produkt> <produkt>Mleko</produkt> <produkt>Cukier</produkt> <produkt>Pasta do zębów</produkt> <produkt ilosc="4">Jedzenie dla kota</produkt> </listaZakupow>
Dokumenty XML mogą być zwalidowane za pomocą tzw. XML Schema. Jest to zestaw reguł, które opisują, jakie elementy mogą zawierać dokumenty pewnego wymyślonego przez nas typu. Dzięki temu, aplikacje które np. wymieniają się danymi korzystając z dokumentów XML, mogą sprawdzić, czy odebrany dokument XML spełnia wymogi dotyczące możliwych tagów i ich wartości. Dla przykładu, gdybyśmy napisali aplikację, która odbiera dokument XML z listą zakupów do zrobienia, to moglibyśmy zdefiniować XML Schema, które definiowałoby, że wszystkie produkty do kupienia muszą być zawarte w tagu nadrzędnym <listaZakupow>, a tagi <produkt> mogą posiadać (ale nie muszą) atrybuty rodzaj i ilosc.
Alternatywa: często stosowanym formatem do wymianych danych jest także JSON, szczególnie w aplikacjach webowych, o którym przeczytasz w kolejnym rozdziale. Z kolei YAML często stosowany jest do zapisu konfiguracji. YAML to nadzbiór JSONa, tzn. oferuje to co JSON plus kilka dodatkowych funkcjonalności.
Czy występuje tylko na projektach Java: nie, XML jest popularnym formatem danych i spotkamy go na różnych projektach.
JSON i YAML¶
JSON to skrót od JavaScript Object Notation. Jest to format opisu danych tekstowych, podobny do XML, ale narzut na metadane jest mniejszy, niż w przypadku danych w formacie XML.
Metadane to dane, które opisują dane. W przypadku plików XML były to tagi i atrybuty. W formacie JSON nie ma tagów – zamiast tego, w cudzysłowach umieszczamy nazwę identyfikującą pewną wartość. Spójrzmy na przykład listy zakupów:
{
"listaZakupow": [
{
"nazwa": "Kawa",
"rodzaj": "rozpuszczalna"
},
{
"nazwa": "Mleko"
},
{
"nazwa": "Cukier"
},
{
"nazwa": "Pasta do zębów"
},
{
"nazwa": "Jedzenie dla kota",
"ilosc": 4
}
]
}
Zauważ, że zbiory danych umieszczamy w nawiasach klamrowych { }. JSON pozwala na przechowywanie danych kilku typów, m. in. liczb, łańcuchów tekstowych, oraz tablic.
JSON służy do opisu dowolnych danych tekstowych, a pliki w formacie JSON mają rozszerzenie .json i można je edytować w dowolnym edytorze, np. Notepad++. Dzięki małemu narzutowi na metadane, format ten jest powszechnie stosowany w aplikacjach webowych do wymiany danych pomiędzy aplikacjami. Często dane wyświetlane na stronach internetowych przesyłane są do Twojej przeglądarki właśnie w formacie JSON.
Aby zwalidować, czy dokument opisany w formacie JSON spełnia pewne wymagania odnośnie rodzaju elementów i ich wartości, wykorzystywane jest tzw. JSON Schema. Aplikacje wymieniające się danymi w formacie JSON mogą sprawdzić, czy wysłany im dokument zawiera elementy i wartości, których się spodziewają.
Powyższe informacje są w zasadzie wystarczającą podstawą jeśli chodzi o korzystanie z formatu JSON.
Możesz spotkać się także z formatem YAML, który jest często używany w plikach konfiguracyjnych. YAML to nadzbiór JSONa, czyli oferuje więcej, niż JSON, m. in. stosowanie komentarzy.
Alternatywa: XML, opisany w poprzednim rozdziale.
Czy występuje tylko na projektach Java: nie, JSON jest popularnym formatem danych i spotkamy go na różnych projektach.
HTTP¶
W dzisiejszych czasach liczba aplikacji webowych jest ogromna. Bardzo często na projektach Javowych tworzy się aplikacje backendowe, które odpytywane są o dane przez różnego rodzaju interfejsy, zwane frontendem.
Backend to część systemu odpowiedzialna za wszystko to, co dzieje się poza widokiem użytkownika – zapis i odczyt danych z bazy danych, generowanie raportów, przygotowywanie zestawu danych do wyświetlenia dla użytkownika, wyszukiwanie danych itd. Frontend to z kolei warstwa aplikacji, z której korzystają bezpośrednio użytkownicy – np. strona internetowa.
Aplikacje frontendowe często komunikują się z aplikacjami backendowymi za pomocą protokołu HTTP, który stanowi standard do wymiany danych w Internecie. Protokół HTTP, czyli Hypertext Transfer Protocol, określa, w jaki sposób należy tworzyć zapytania o pewne dane, oraz w jaki sposób te dane odsyłać. Komunikacja za pomocą HTTP ma postać zapytanie-odpowiedź.
Dla przykładu, klient, którym mogłaby być przeglądarka internetowa, wysyła do serwera Google zapytanie o otrzymanie wyników wyszukiwania stron poświęconych programowaniu w Javie. Serwer otrzymuje takie zapytanie i odsyła do przeglądarki listę znalezionych stron. Przeglądarki z włączonym trybem developerskim mogą wyświetlać treść takich zapytań:
Request URL: https://www.google.com/search?source
=hp&ei=T_iOXpoM6qCuBPL0lbgJ&q=programowanie+w+javie&oq
=programowanie+w+javie&gs_lcp=CgZwc3ktYWIQAzICCAAyAggA
MgIIADICCAAyAggAMgIIADICCAAyAggAMgUIABDNAjIFCAAQzQI6BQ
gAEIMBOgQIABADSisIFxInNTBnNzlnNjZnOTlnMTA0ZzgzZzgzZzg0
ZzYzZzYyZzY0ZzYwZzYySh0IGBIZMWcxZzFnMWcxZzFnMWcxZzFnMW
c1ZzVnMlDUDliSHWCEHmgAcAB4AIABWIgBiQqSAQIyMpgBAKABAaoB
B2d3cy13aXqwAQA&sclient=psy-ab&ved=0ahUKEwja743jkNvoAh
VqkIsKHXJ6BZcQ4dUDCAY&uact=5
Request Method: GET
Status Code: 200
Request URL zawiera adres, na jaki zapytanie zostanie wysłane, oraz jego argumenty, które znajdują się po znaku zapytania ?. Zwróć uwagę na jeden z tych argumentów – jego nazwa to q, a wartość to programowanie+w+javie (spacje zamieniane są na znaki +). Parametr q określa frazę, którą Google ma znaleźć. Mógłbyś otworzyć zakładkę w swojej przeglądarce i wpisać po prostu adres https://www.google.com/search?q=programowanie+w+javie, co spowodowałoby wysłanie zapytania do znalezienia stron z podaną frazą. Zapytanie na powyższym listingu jest dłuższe, bo Google dodało jeszcze kilka istotnych dla siebie parametrów.
Pod Request URL znajduje się Request Method, które jest ważnym pojęciem związanym z HTTP. Protokół HTTP oferuje kilka metod, zwanych też czasownikami, które stosujemy do tworzenia odpowiedniego rodzaju zapytań. Są to m. in.:
- GET – służy do pobierania danych,
- POST i PUT – służą do wysyłania danych o zasobach, które mają zostać utworzone/zaktualizowane,
- DELETE – oznacza, że zasób, o którym mowa w zapytaniu, ma zostać usunięty.
Zapytania i odpowiedzi HTTP mają także statusy, które przekazują dodatkowe informacje. Status 200 to OK, a 404 to Nie znaleziono. Możliwe, że widziałeś kod błędu 404, gdy próbowałeś wejść na stronę korzystając z linku, w którym popełniony był błąd bądź strona już nie istniała.
Zapytania mogą zawierać także nagłówki, które niosą dodatkowe informacje dla serwera, do którego kierowane jest zapytanie, np. kodowanie znaków i typ przesyłanych danych.
W wyniku otrzymanego powyższego zapytania (za pośrednictwem przeglądarki Opera), serwer google, które to zadania obsłużył, odesłał do mojej przeglądarki stronę internetową z listą stron, które pasowały do wzorca wyszukiwania "programowanie w javie".
Nie musisz znać szczegółowych informacji na temat HTTP – wystarczy, że na początek będziesz wiedział do czego służy HTTP. Klienci i serwery wymieniają się danymi za pomocą zapytań i odpowiedzi, który opisywane są przez metody (czasowniki), takie jak GET i POST, oraz mają statusy i nagłówki.
W Javie istnieją biblioteki ułatwiające korzystanie z HTTP, np. w Springu, dlatego wystarczą podstawy, aby móc korzystać z tego protokołu.
Czy występuje tylko na projektach Java: nie, HTTP to standard występujący powszechnie w świecie informatyki.
REST¶
REST to standard określający sposób, w jaki mają być tworzone Web Service'y, czyli usługi, które pozwalają na operowanie na pewnych danych, w tym pobieranie ich, tworzenie, aktualizację, oraz usuwanie.
Web Service'y REST definiują pewne zasoby, do których odnosimy się za pomocą odpowiednich adresów URL, np. adres http://pewnastrona.com/zamowienia mógłby być adresem stosowanym, aby operować na zamówieniach. Dodatkowo, obiekty takie jak zamówienia mogłyby mieć przypisane do nich produkty, więc moglibyśmy odnosić się do nich za pomocą http://pewnastrona.com/zamowienia/produkty, a do konkretnego produktu w zamówieniu, np. do pierwszego z nich, poprzez http://pewnastrona.com/zamowienia/produkty/1.
Aby manipulować zasobami REST, korzystamy z protokołu HTTP, który opisałem w poprzednim rozdziale, oraz jego metod: GET, POST, PUT, oraz DELETE. Dzięki wysłaniu zapytania GET na (przykładowy) adres http://pewnastrona.com/zamowienia otrzymalibyśmy listę zamówień, a za pomocą metody POST wraz z danymi o nowym zamówieniu moglibyśmy kazać Web Service'owi utworzyć i zapisać w bazie danych nowe zamówienie.
REST stał się bardzo popularny w ostatnich latach i otrzymał wsparcie w takich frameworkach jak Spring. Napisanie aplikacji udostępniającej pewne dane poprzez REST jest relatywnie proste. Mając skonfigurowany Mavenowy projekt Spring Boot, poniższy prosty program jest wystarczający do udostępnienia lokalnie zasobu hello poprzez RESTowy kontroler. Kontrolery odbierają zapytania i odsyłają odpowiedzi:
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class HelloController {
@GetMapping("/hello")
public String greeting(
@RequestParam(value = "name", defaultValue = "nieznajomy") String name) {
return "Hello " + name;
}
}
Po uruchomieniu programu, w którym zawarta jest ta klasa, możemy w naszej przeglądarce internetowej wejść na lokalny adres naszego komputera localhost. Nasz program będzie domyślnie nasłuchiwał zapytań na porcie 8080. Poprzez przeglądarkę możemy wysłać zapytanie GET do zasobu hello, wpisując jako adres w przeglądarce http://localhost:8080/hello?name=World. Do zapytania dodaliśmy parametr name. Nasza aplikacja odeśle do przeglądarki komunikat Hello World, który zostanie nam wyświetlony.
Nie musisz być zaznajomiony ze szczegółami REST. Najważniejsze, byś rozumiał, że Web Service'y REST udostępniają pewne zasoby, na których operujemy za pomocą metod protokołu HTTP: GET, POST, PUT, oraz DELETE. Warto także znać podstawy obsługi REST – zarówno odbioru zapytań, jak w powyższym przykładzie, jak i ich wysyłania za pomocą np. Springowej klasy RestTemplate.
Alternatywa: zamiast tworzyć aplikacje oparte na REST, możemy np. stworzyć SOAP Web Service, który do wymiany informacji korzysta z plików XML.
Czy występuje tylko na projektach Java: nie, REST to standard występujący powszechnie w świecie informatyki.
HTML i CSS¶
HTML to HyperText Markup Language. Jest to język, którym opisujemy strukturę dokumentów wyświetlanych na stronach internetowych. Większość stron internetowych, które odwiedzasz, mają swoją treść opisaną właśnie za pomocą HTMLa.
Dokumenty HTML zawierają treść tekstową, która opisana jest poprzez użycie tzw. tagów.
Tagi to elementy zawarte pomiędzy nawiasami ostrymi: < oraz >. Większość tagów po otwarciu powinna zostać zamknięta tagiem, który zaczyna się od nawiasu ostrego i znaku slash: </
Spójrz na poniższy przykład:
<p>To jest paragraf.</p>
W powyższej linii tekst To jest paragraf. zawarty jest w tagu <p> (p jak paragraph). Tag ten stosujemy do oddzielenia od siebie paragrafów w dokumencie. Zauważ, że koniec paragrafu zaznaczyliśmy za pomocą tagu zamykającego </p>.
Dokumenty HTML zazwyczaj umieszczamy w "głównym" elemencie o nazwie <html>. Treść tego elementu dzielimy na dwie części – metadane umieszczamy w tagu <head>, a ciało dokumentu w tagu <body>. Tagi mogą mieć także atrybuty określające np. klasę stylu CSS, które zaraz omówię.
Możesz stworzyć swoją pierwszą stronę internetową zapisując poniższy dokument w pliku o nazwie np. mojaStrona.html i otwierając ją w przeglądarce takiej jak Firefox czy Opera:
<html>
<head>
<title>Moja pierwsza strona</title>
</head>
<body>
<h1>Witaj!</h1>
<p>To moja <strong>pierwsza strona!</strong></p>
</body>
</html>
Tag <h1> oznacza nagłówek najwyższego rzędu, a <strong> określa ważny tekst. Powinienieś w przeglądarce zobaczyć stronę podobną do poniższej:

Najnowsza wersja HTML zawiera wiele tagów, z których możemy korzystać w naszych dokumentach. Strony wyglądałyby jednak ponuro, gdybyśmy nie mogli ich elementom przypisać kolorów i efektów. W tym celu stosujemy CSS.
CSS to skrót od Cascading Style Sheets. Jest to język stosowany do zmiany sposobu, w jaki prezentowane są dokumenty opisane za pomocą HTML.
CSS daje nam ogromne możliwości jeśli chodzi o to, jak mają wyglądać poszczególne elementy strony. Gdy wchodzisz na stronę internetową, wszystkie kolory, rozmiary i rodzaje czcionek, marginesy, obramowania, a nawet rozmieszczenie elementów względem siebie – zdefiniowane są za pomocą CSS. Style CSS pozwalają nawet na zmianę wyglądu stron na różnych urządzeniach – strona może wyglądać inaczej na komputerze, tablecie, oraz telefonie.
Style CSS zapisujemy w plikach o rozszerzeniu .css lub umieszczamy je bezpośrednio w dokumentach HTML. Aby zmienić wygląd danego elementu strony, korzystamy z selektorów, po których w nawiasach klamrowych umieszczamy cechy danego stylu. Selektor to sposób na identyfikację jednego lub więcej elementów w dokumentach HTML. Najprostszym selektorem jest po prostu nazwa tagu, który chcemy "ostylować". Dla przykładu, aby zmienić wygląd wszystkich nagłówków na naszej stronie, moglibyśmy zastosować następujący styl CSS:
h1 {
border: solid 1px blue;
padding: 2px 10px;
background-color: lightsteelblue;
}
Ten styl za pomocą właściwości border dodaje ramkę naokoło nagłówków opisanych tagiem HTML <h1>. Ponadto, oddala treść nagłówka od ramki i zmienia kolor tła.
Do elementów na stronie możemy odnosić się także za pomocą klas, które potem możemy ustawić jako atrybut konkretnego tagu na naszej stronie. Poniżej znajduje się prosty przykład dokumentu HTML z zagnieżdżonymi stylami CSS:
<html>
<head>
<title>Moja pierwsza strona</title>
<style>
body {
width: 60%;
margin: 20px auto;
background-color: lightblue;
}
h1 {
border: solid 1px blue;
padding: 2px 10px;
background-color: lightsteelblue;
}
p {
font-size: 16pt;
}
p.istotnaInformacja {
border: solid 1px red;
padding: 4px 10px;
background-color: #ccffff;
font-style: italic;
}
</style>
</head>
<body>
<h1>Witaj!</h1>
<p>To moja <strong>pierwsza strona!</strong></p>
<p class="istotnaInformacja">Pamiętaj, aby nie dzielić przez 0!</p>
</body>
</html>
Jest to ten sam dokument, który widzieliśmy przy omawianiu HTML, ale z dodanymi stylami CSS oraz dodatkowym paragrafem, który ma ustawioną klasę istotnaInformacja. Ten konkretny paragraf będzie wyglądał inaczej niż pierwszy paragraf, ponieważ w stylach CSS zdefiniowaliśmy dedykowane dla tej klasy właściwości. Powyższa strona wygląda teraz następująco:
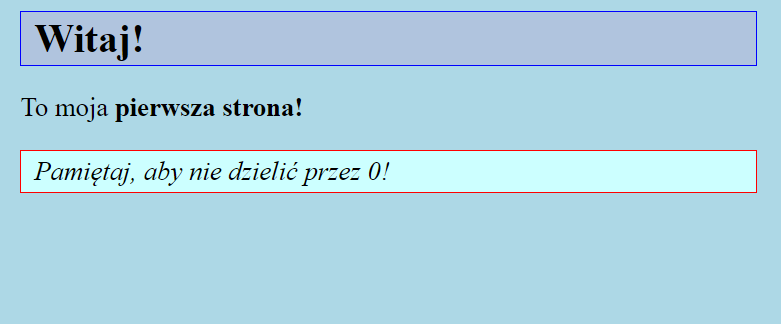
Co powinieneś umieć: wystarczy rozumieć, do czego HTML służy, jak opisuje się nim dokumenty oraz zaznajomić się z najczęściej używanymi tagami. Jeżeli natkniesz się na tag, którego nie znasz, wystarczy sprawdzić w Internecie jego znaczenie. Inaczej sprawa ma się ze stylami CSS – pozwalają one na tak zaawansowaną manipulację wyglądem stron CSS, że ich nauka na zaawansowanym poziomie może zająć lata. Na szczęście, jako programista Java, wystarczy, że będziesz rozumiał do czego style CSS są używane, oraz nauczyć się podstaw stylowania prostych dokumentów, pisania selektorów oraz nazw najczęściej stosowanych właściwości.
Alternatywa: trudno szukać alternatywy dla HTML i CSS ponieważ są tak popularne, że istnieje mała szansa, aby się z nimi nie spotkać.
Czy występuje tylko na projektach Java: nie, HTML i CSS to powszechnie stosowane technologie.
Systemy operacyjne Windows i Linux¶
Wszystkie operacje wykonywane podczas tworzenia oprogramowania odbywają się w pewnym systemie operacyjnym. Na projektach programistycznych są to głównie systemy Windows oraz Linux, przy czym mam tutaj na myśli komputery programistów. Zależnie od firmy, możemy także dostać do pracy komputer z systemem MacOS.
Serwery, czyli komputery, na których docelowo działają tworzone przez nas np. aplikacje webowe, zazwyczaj korzystają z systemów Linux. Dlatego też warto poznać podstawy tego systemu nawet, jeżeli na laptopie, który dostaniemy do pracy, zainstalowany będzie system Windows. Prędzej czy później przyjdzie nam się zalogować do serwera i w terminalu wykonać pewne zadanie, jak na przykład sprawdzić logi wykonania programu by dowiedzieć się, dlaczego program przestał działać.
Nie musisz być ekspertem od systemów operacyjnych – wystarczy, żebyś znał podstawy korzystania z linii poleceń systemu Windows i terminala systemu Linux oraz był w stanie zainstalować i skonfigurować wymagane przez siebie do pracy aplikacje. Znajomość skrótów klawiaturowych także się przydaje, ponieważ znacząco przyspieszają one pracę. Duża część z nich jest wspólna dla różnych systemów operacyjnych (więcej o skrótach klawiaturowych znajdziesz w moim artykule na ten temat).
Alternatywa: jeżeli będziesz pracował na systemie MacOs, to znajomość systemu Windows raczej Ci się nie przyda, jednak istnieje duża szansa, że serwery będą działały na systemie Linux. Tak czy inaczej, warto moim zdaniem znać podstawy systemów typu Linux.
Czy występuje tylko na projektach Java: nie, systemy operacyjne raczej nie zależą od technologii wykorzystywanych na projekcie.
JUnit i testy jednostkowe¶
Podstawowe testy sprawdzające, czy nasze programy działają zgodnie z naszymi założeniami, to testy jednostkowe.
Testy jednostkowe sprawdzają, czy metody (czyli pewne fragmenty kodu źródłowego programów, które mają do wykonania pewne zadanie) wykonują powierzone im zadanie i zwracają poprawne wyniki.
Testy, poza sprawdzeniem, że nasz kod w tej chwili spełnia nasze oczekiwania, stoją także na straży przed potencjalnym wprowadzeniem błędów (zwanych bugami) w kodzie w przyszłości. Po modyfikacji kodu, np. związanej z dodaniej nowej funkcjonalności, uruchamiamy testy i sprawdzamy, czy w wyniku naszych zmian nie zepsuliśmy aplikacji.
JUnit to biblioteka, której używamy do uruchamiania testów naszego kodu. JUnit znajdzie wszystkie klasy testowe, uruchomi znalezione w nich metody z testami, a na końcu wyświetli raport z podsumowaniem, ile testów zostało wykonanych i ile z nich zakończyło się sukcesem.
JUnit dostarcza także wiele przydatnych metod, których używamy do sprawdzania, czy spodziewany przez nas wynik wywołania pewnego fragmentu kodu jest zgodny z naszymi oczekiwaniami. Takie pomocnicze metody to asercje, zapewniające spełnienie pewnych warunków. Jeżeli warunek nie będzie spełniony, to JUnit zaklasyfikuje test zawierający tę asercję jako zakończony porażką.
Poniżej znajdziesz prosty przykład testów jednostkowych korzystających z JUnit. Jest to klasa testowa z mojego kursu Podstawy Maven:
package com.kursjava.maven;
import static org.junit.Assert.assertEquals;
import org.junit.Test;
public class FactorialTest {
@Test
public void shouldReturnFactorial() {
assertEquals(120, FactorialCounter.factorial(5));
}
@Test(expected = IllegalArgumentException.class)
public void shouldThrowExceptionForInvalidArgument() {
FactorialCounter.factorial(-1);
}
}
assertEquals to metoda pomocnicza udostępniana przez JUnit. Porównuje ona spodziewaną wartość, czyli swój pierwszy argument, z faktyczną wartością zwracaną przez testowaną metodę, która w tym przypadku jest metodą factorial.
Wymagania odnośnie pisania testów jednostkowych to podstawowe zrozumienie, do czego te testy służą, oraz zrozumienie, jak pisać kod, aby był testowalny. Podstawy JUnit obejmują uruchamianie testów oraz wykorzystywanie dostarczanych przez JUnit metod asercji.
Alternatywa: innym frameworkiem wykorzystywanym do testów jednostkowych jest TestNG, ale z mojego doświadczenia, JUnit jest częściej spotykany.
Czy występuje tylko na projektach Java: testy jednostkowe są używane na różnych projektach, niezależnie od użycia języka Java. JUnit jest dedykowany dla Javy, ale poznając jego podstawy łatwiej będzie Ci ogólnie tworzyć testy jednostkowe.
Code review¶
Po napisaniu kodu źródłowego zawsze warto, aby inna osoba spojrzała na niego i oceniła, czy coś można by poprawić. Często też takim osobom udaje się wyłapać potencjalne błędy i zapobiec ich wprowadzeniu do systemu.
Taki proces to code review. Jest to proces analizy kodu źródłowego w celu znalezienia potencjalnych błędów przez osoby, które go nie pisały. Gdy programista wykona zmiany w kodzie źródłowym, przed wgraniem ich do "głównej" wersji systemu (czyli takiej, która ma zostać udostępniona użytkownikom) przekazuje te zmiany do recenzji programistom, z którymi pracuje na projekcie.
Code review zazwyczaj bardzo dobrze się sprawdza i pozwala, zarówno, na zminimalizowanie potencjalnych błędów w programie, jak i ogólne podniesienie jakości kodu i wymianę wiedzy pomiędzy programistami.
Istnieją różne narzędzia, które umożliwiają przeprowadzanie code review w łatwy sposób. Jednym z nich jest BitBucket, którego głównym zadaniem jest udostępniania serwerów systemu kontroli wersji Git. Gdy programista, korzystający z repozytorium Git, napisze kod, który chciałby oddać do code review, wystarczy, że wyśle swoje zmiany na BitBucket, a nąstępnie utworzy tzw. pull request, czyli prośbę o wgranie jego zmian w kodzie źródłowym do głównej wersji systemu. Musi wtedy wskazać jedną bądź więcej osób, które będą musiały zatwierdzić wprowadzane przez niego zmiany. Mogą one dawać komentarze do kodu, a autor może go poprawiać, jeżeli recenzenci znajdą potencjalne problemy. Gdy zmiany zostaną zaakceptowane, wchodzą one do głównej wersji systemu.
Dobrze wiedzieć, do czego code review służy i jaki jest proces jego przeprowadzania. Możesz stworzyć darmowe repozytorium np. na BitBucket i poćwiczyć tam proces code review oraz tworzenie pull requestów.
Czy występuje tylko na projektach Java: nie, code review nie jest zależne od języka programowania.